
Batch Decoding with Glaciers
Why Glaciers?

You can read a Twitter thread version of this post here.

Permissionless access to data is one crucial aspect of social consensus. The motto of blockchains, “Verify, don’t trust!” tells you exactly that. Take DeFi apps as an example; they are not based on faith; they prevail because anyone can validate them. At any point in time, you can evaluate their trust assumptions, see how much liquidity, collateral, and debt they have, and make them accountable.
Events and call data are the primary data source of Ethereum (and other EVM chains). Web apps, analytics websites, Dune dashboards, and AI models are created using events as the most basic data primitive. Events are then transformed, combined, and grouped to create a metric in a chart or a table.
Despite writing (submitting transactions) into blockchain being relatively decentralized, reading is not. Much of the data remains siloed in enterprise databases. Companies running crypto data businesses or applications often face the dilemma of whether to index blockchain data themselves. However, this decision comes with significant engineering challenges and costs. Managing crypto data is inherently expensive—not just in terms of computational and storage resources but also due to the engineering effort required.
The crypto data flow can be broken into three essential steps:
Extraction (request pipelines)
Decoding
Transformations
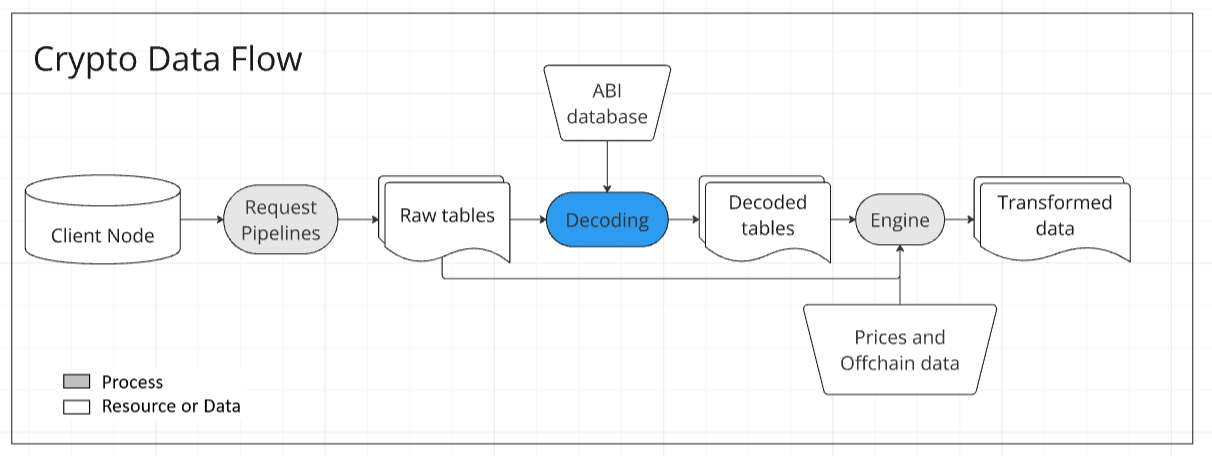
Accessing on-chain data typically begins with requesting it from nodes via an interface like a JSON-RPC. Open-source extraction tools such as Cryo and EQL have emerged to provide efficient and streamlined solutions for extracting blockchain data, including blocks, transactions, logs, and traces. They output the data in manipulation-friendly formats like Parquet, CSV, or data frames. By simplifying the extraction process, they eliminate the need for complex custom pipelines and can integrate seamlessly into ELT (Extract, Load, Transform) workflows, making blockchain data more accessible and cheaper.
Skipping decoding for now, transformation is a well-supported stage in the industry, as it is not unique to the Web3 ecosystem. The tools and approaches used for transformation vary greatly across organizations, ranging from straightforward solutions like Python notebooks to sophisticated data warehouse infrastructures.
Decoding is the process of translating raw events and traces into a human-readable format. It leverages the contract ABI to identify function and parameter names. This step adds critical context—clarifying what each field or value represents—and ensures accurate type casting. Decoding can also be thought of as the first standardized transformation in the data flow, which most data need to go through.
Decoding has remained a significant blind spot in the industry until now. While basic decoding is supported by libraries like alloy-rs, ethers.js, and web3.py—commonly used to help developers interact with EVM—its application has been largely overlooked when processing data at scale or in batches.
What do Glaciers include?
Large-scale decoding requires users to maintain an extensive ABI database. ABIs are files that serve as a translation guide for understanding the data structure. Since ABIs cannot be directly retrieved from the blockchain, they are typically sourced from off-chain providers like Etherscan, where contracts are submitted for transparency and auditability.
Glaciers provide data engineers with functions to aggregate multiple ABI files in a folder, a single ABI, or even a manually inputted ABI into tables for their project needs. Looking ahead, we plan to enable automatic ABI downloads from providers and, longer in the future, create an open-source database optimized for decoding purposes.
Decoding logs from contracts for which the code or ABI is unknown is still possible. This is because contracts often reuse code from other contracts, meaning functions and events frequently share the same signature (name and parameters). In such cases, the ABI of another contract can be used to decode the logs.
Glaciers use algorithms to match onchain information from logs and signature hashes (topic0, 4-byte) with any available ABI. It’s particularly useful for analytics because it allows the exploration of contract data without needing prior knowledge of the contract's code. While this approach necessitates handling potential mismatches, future updates will incorporate more sophisticated algorithms that use onchain analytics to identify the best-matching contracts and ABIs.
Finally, raw data from function calls or events is decoded using a User-Defined Function (UDF), which adds decoded columns to the schema. Glaciers provide functions to decode multiple log files in folders and single files converted to data frames. The architecture makes batch decoding extremely fast—even without optimization; it can decode an entire day's worth of Ethereum logs in less than a minute, making decoding the entire blockchain history a practicable endeavor.
How can you use Glaciers?
Glaciers offer versatile functionality for different users in the Ethereum ecosystem:
For Data Providers:
Data providers can run indexers to extract all EVM logs and traces, then elevate your capabilities with Glaciers. By decoding raw data into human-readable tables, Glaciars transforms your service into a “Decoded Streaming Service.” This allows you to deliver enriched datasets that are ready for analytics, enabling data scientists to seamlessly create dashboards and insights for any protocol by filtering specific contracts from the broader dataset.
For Protocol Developers:
Index all your project's data, including interacting contracts, in a separate pipeline. With Glaciers, you can decode all indexed data at once by simply providing your ABIs, effectively decoupling indexing from decoding. This streamlined approach simplifies workflows, making it effortless to run backfills and maintain consistency across your data pipelines.
For Developers:
Integrate Glaciers as a library into your projects to avoid writing custom decoding functions. This saves time and effort while ensuring robust and reliable decoding functionality for your applications.
Making Blockchain Data a Public Commodity
Glaciars is an open-source project. By providing powerful decoding capabilities, Glaciars aims to make onchain data more accessible and usable for everyone. We believe that when the right tools are freely available, more teams can take ownership of their data pipelines—whether by indexing their own data or becoming data providers themselves. This creates a more competitive and democratized ecosystem, turning blockchain data into a commodity accessible to all, not just a select few.
Initiated by the determination of a single developer to lower the barriers to blockchain data, Glaciers will always remain open and available to everyone. To sustain and expand this vision, we are seeking financial support—whether through grants, contributions, or collaborations. In exchange, grantors can directly influence the project’s roadmap, prioritizing features that align with their needs. Additionally, we can highlight your support, providing both visibility and positive brand association. If you’re interested in collaborating on this initiative, get in touch.
Yule
X (yulesa):
https://x.com/yulesa
Telegram (yuleandrade):
t.me/yuleandrade
Discord User (yulesa):
discord.com/users/yulesa