Using Glaciers for Analytics
Decoding and Analyzing Ethereum Data

You can read a Twitter thread version of this post here. This example is available in the Glaciers repo, together with all the necessary files.
Glaciers is a robust tool for decoding Ethereum logs and transforming raw blockchain data into insights. In this post, we’ll explore how to use Glaciers to decode logs and analyze data. For the example, we will gather and decode all the data required to replicate the UniswapV2 Analytics page. It demonstrates fetching raw logs, decoding them, and generating analytics using Python.
We chose this approach because the amount of data to process is small enough to allow runtime requests and execution in a simple example. For production use, Glaciers offers significant advantages by decoupling the data flow process. Indexing (requests) can be executed separately for multiple contracts simultaneously, independently handling errors and backfilling data when needed. Decoding can then occur in batches, leveraging all available ABIs at once. Finally, the decoded data can serve as a foundation for exploration and further transformations (Analytics).
Preparations
# You can install the necessary libraries using pip
# `pip install polars glaciers hypersync requests toml pandas nbformat plotly`, or do `uv sync` if you are using uv.
# Import the necessary libraries
import polars as pl
import glaciers as gl
import requests
import hypersync
from hypersync import BlockField, LogField
import asyncio
import toml
import plotly.express as pxFetching Raw Logs
Glaciers assumes you already have your raw logs indexed. Many tools exist to index EVM data, but for this example, we are using Envio’s HyperSync.
HyperSync is a high-performance alternative to JSON-RPC, avoiding the limitations of public free RPC providers like rate limits and error handling. HyperSync allows you to filter blocks, logs, transactions, and traces using queries.
In this example, we query only logs from the uniV2RAIETH pool contract starting at block 11,848,623 (the deployment block). Yet, nothing prevents fetching data for multiple (or maybe all) contracts at the same time.
Additionally, we extract block timestamps and join them with the logs, creating a final table where each log includes a timestamp.
# Define the contract address, uniV2RAIETH pool contract.
contract = ["0x8aE720a71622e824F576b4A8C03031066548A3B1"]
# Create hypersync client using the mainnet hypersync endpoint (default)
client = hypersync.HypersyncClient(hypersync.ClientConfig())
# Define the query
query = hypersync.Query(
from_block=11_848_623,
logs=[hypersync.LogSelection(address=contract)],
field_selection=hypersync.FieldSelection(
block=[
BlockField.NUMBER,
BlockField.TIMESTAMP
],
log=[
LogField.LOG_INDEX,
LogField.TRANSACTION_HASH,
LogField.ADDRESS,
LogField.TOPIC0,
LogField.TOPIC1,
LogField.TOPIC2,
LogField.TOPIC3,
LogField.DATA,
LogField.BLOCK_NUMBER,
],
)
)
# Collect to files the logs and blocks
await client.collect_parquet(query=query, path="data", config=hypersync.ClientConfig())
# Read the logs and blocks
ethereum__logs__uniV2RAIETH = pl.read_parquet("data/logs.parquet")
ethereum__blocks__mainnet = pl.read_parquet("data/blocks.parquet")
# Join the logs and blocks
ethereum__logs__uniV2RAIETH = ethereum__logs__uniV2RAIETH.join(
ethereum__blocks__mainnet,
left_on=["block_number"],
right_on=["number"],
how="inner"
# Convert to timestamp and rename the timestamp to block_timestamp
).with_columns(
(pl.col("timestamp").bin.encode('hex').str.to_integer(base=16)*1000).cast(pl.Datetime(time_unit="ms")).alias("block_timestamp")
).drop(["timestamp"])
# Write the logs to a parquet file
ethereum__logs__uniV2RAIETH.write_parquet("data/ethereum__logs__uniV2RAIETH.parquet")
ethereum__logs__uniV2RAIETH.head(3)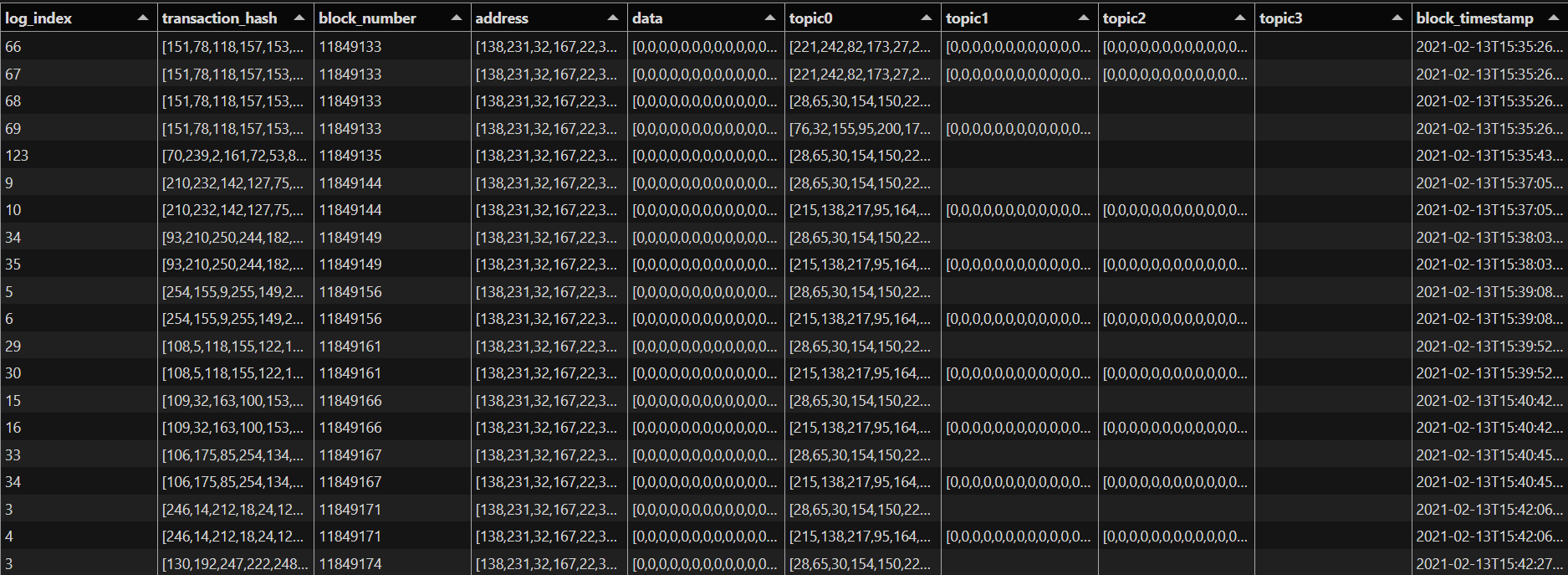
Decoding
Configuring Glaciers
To ensure smooth operation, Glaciers rely on configuration parameters. These parameters can be modified using two methods:
1. TOML Configuration File: Using set_config_toml specifies all the changes in a TOML file.
2. Programmatic Configuration: Use the set_config method to update specific fields.
The get_config method retrieves all current configurations, enabling easy inspection. Configurations are key-value pairs in a dictionary format. Deeper-level keys are accessed via dot notation. Key configurations include:
Schema for raw input logs
Output formats
Parallel thread parameters for decoding files
# Use a toml config file, to set the config.
gl.set_config_toml("example_glaciers_config.toml")
# Set the config fields instead of using a toml file. It has the same effect as above.
gl.set_config(field="decoder.output_hex_string_encoding", value=True)
gl.set_config(field="abi_reader.output_hex_string_encoding", value=True)
# Print the config
config = toml.loads(gl.get_config())
print(config["abi_reader"]){'unique_key': ['hash', 'full_signature'], 'output_hex_string_encoding': True}
Create an ABI dataframe
The first step in decoding is creating an ABI DataFrame. This table consolidates data from multiple ABIs and serves as input for the decoding process. Typically, each contract address corresponds to an ABI file. Glaciers provides functions to aggregate:
Multiple ABI files from a folder
A single ABI (our simplified case)
Manually inputted ABI data
Since our example is only one ABI, we can copy it from here. The generated file contains essential information, including hashes and full signatures for events and functions, all compiled into one reference table.
# Read one ABI file
UniswapV2PairABI = gl.read_new_abi_file("data/0x8ae720a71622e824f576b4a8c03031066548a3b1.json")
# Write the ABI to a parquet file
UniswapV2PairABI.write_parquet("data/UniswapV2PairABI.parquet")
UniswapV2PairABI.tail(7)
Batch decoding
With the ABI DataFrame ready, the real action begins. Raw event data is matched with ABI items, and each row is decoded using a User Defined Function (UDF). This process adds decoded columns to the schema, enriching the raw logs with details like:
Event
nameEvent
full_signatureEvent
anonymousstatusDecoded values (
event_values,event_keys,event_json)
Glaciers supports batch decoding for multiple files, single files, or data frames, and the entire process can be executed with a single line of code.
# Decode the logs
decoded_logs_df = gl.decode_file(decoder_type="log", file_path="data/ethereum__logs__uniV2RAIETH.parquet", abi_db_path="data/UniswapV2PairABI.parquet")
# Drop the columns that are not needed anymore
decoded_logs_df = decoded_logs_df.drop(["topic0", "topic1", "topic2", "topic3", "data", "full_signature", "anonymous"])
decoded_logs_df.head(3)
Analytics
Exploring and Filtering Data
Decoded logs provide a wealth of data for analytics. The resulting table includes all contracts and events, with event keys and values nested in JSON objects for flexibility.
When decoding a single contract, as in this example, the data is somehow straightforward. However, decoding multiple or all contracts introduces greater exploration potential. You can inspect different contracts or event fields, and determine what information is valuable for analytics. This is similar to selecting tables in Dune Analytics.
#show all events names and keys
decoded_logs_df.group_by(["name", "event_keys"]).len()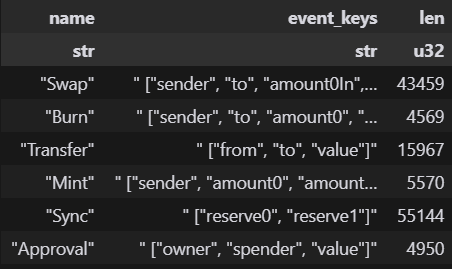
The Decoded Logs table contains all contracts and events together. This constrains that `event_keys` and `event_values` be nested within JSON objects. By listing all the keys, it’s easy to filter and unnest the values into individual tables.
Filtering: Filter tables by the required contracts and events. Filtering can be done on-demand, narrowing data to what you need.
Unnesting Values: After filtering, unnest the values into individual columns since all rows now share the same structure.
mint_df = decoded_logs_df\
.filter(pl.col("name") == "Mint")\
.filter(pl.col("address") == "0x8ae720a71622e824f576b4a8c03031066548a3b1")\
.with_columns(
pl.col("event_values").str.json_decode().list.get(0).alias("sender"),
pl.col("event_values").str.json_decode().list.get(1).cast(pl.Float64).alias("amount0"), #amount0 is the amount of RAI
pl.col("event_values").str.json_decode().list.get(2).cast(pl.Float64).alias("amount1"), #amount1 is the amount of ETH
)\
.drop(["event_values", "event_keys", "event_json"])
swap_df = decoded_logs_df\
.filter(pl.col("name") == "Swap")\
.filter(pl.col("address") == "0x8ae720a71622e824f576b4a8c03031066548a3b1")\
.with_columns(
pl.col("event_values").str.json_decode().list.get(0).alias("sender"),
pl.col("event_values").str.json_decode().list.get(1).alias("to"),
pl.col("event_values").str.json_decode().list.get(2).cast(pl.Float64).alias("amount0In"), #amount0In is the amount of RAI
pl.col("event_values").str.json_decode().list.get(3).cast(pl.Float64).alias("amount1In"), #amount1In is the amount of ETH
pl.col("event_values").str.json_decode().list.get(4).cast(pl.Float64).alias("amount0Out"), #amount0Out is the amount of RAI
pl.col("event_values").str.json_decode().list.get(5).cast(pl.Float64).alias("amount1Out"), #amount1Out is the amount of ETH
)\
.drop(["event_values", "event_keys", "event_json"])
burn_df = decoded_logs_df\
.filter(pl.col("name") == "Burn")\
.filter(pl.col("address") == "0x8ae720a71622e824f576b4a8c03031066548a3b1")\
.with_columns(
pl.col("event_values").str.json_decode().list.get(0).alias("sender"),
pl.col("event_values").str.json_decode().list.get(1).alias("to"),
pl.col("event_values").str.json_decode().list.get(2).cast(pl.Float64).alias("amount0"), #amount0 is the amount of RAI
pl.col("event_values").str.json_decode().list.get(3).cast(pl.Float64).alias("amount1"), #amount1 is the amount of ETH
)\
.drop(["event_values", "event_keys", "event_json"])
sync_df = decoded_logs_df\
.filter(pl.col("name") == "Sync")\
.filter(pl.col("address") == "0x8ae720a71622e824f576b4a8c03031066548a3b1")\
.with_columns(
pl.col("event_values").str.json_decode().list.get(0).cast(pl.Float64).alias("reserve0"), #reserve0 is the amount of RAI
pl.col("event_values").str.json_decode().list.get(1).cast(pl.Float64).alias("reserve1"), #reserve1 is the amount of ETH
)\
.drop(["event_values", "event_keys", "event_json"])
transfer_df = decoded_logs_df\
.filter(pl.col("name") == "Transfer")\
.filter(pl.col("address") == "0x8ae720a71622e824f576b4a8c03031066548a3b1")\
.with_columns(
pl.col("event_values").str.json_decode().list.get(0).alias("from"),
pl.col("event_values").str.json_decode().list.get(1).alias("to"),
pl.col("event_values").str.json_decode().list.get(2).cast(pl.Float64).alias("value"),
)\
.drop(["event_values", "event_keys", "event_json"])
swap_df.head(3)
Fetching price
For our analytics, we need additional input data: daily ETH prices. We retrieve the last 365 days of historical prices using the free CoinGecko API.
# Define the connection with a price provider.
price_api_url = "https://api.coingecko.com/api/v3/coins/ethereum/market_chart?vs_currency=usd&days=365&interval=daily"
# Define the request params.
headers = {"accept": "application/json"}
# Request, receive and store the ETH price.
eth_price = requests.get(price_api_url, headers=headers).json()
# Convert the price to a dataframe
eth_price_df = pl.DataFrame(
eth_price["prices"],
schema=["datetime", "eth_price_usd"],
orient="row",
)
# Convert the datetime to a date type
eth_price_df = eth_price_df.with_columns(
pl.col("datetime").cast(pl.Int64).cast(pl.Datetime(time_unit="ms")).dt.date().alias("datetime")
)
# Write the dataframe to a parquet file
eth_price_df.write_parquet("data/coingecko__eth_price.parquet")
eth_price_df.head()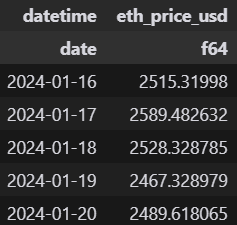
Volume, liquidity, and price
Finally, we use the individual events table to transform the data into analytics. It requires some understanding of the interworkings of the contracts we are dealing with.
1. Daily Volume: Aggregating all swap events in the pool. Multiply the volume in ETH terms by the ETH price to calculate USD volume.
volume_df = swap_df.select(
pl.col("block_timestamp").dt.date().alias("datetime"),
((pl.col("amount0In")+pl.col("amount0Out"))/1e18).alias("Vol (RAI)"),
((pl.col("amount1In")+pl.col("amount1Out"))/1e18).alias("Vol (ETH)"),
).group_by(["datetime"]).agg(
pl.col("Vol (RAI)").sum().alias("Vol (RAI)"),
pl.col("Vol (ETH)").sum().alias("Vol (ETH)"),
).join(
eth_price_df, on="datetime", how="inner"
).with_columns(
(pl.col("Vol (ETH)")*pl.col("eth_price_usd")).alias("Vol (USD)"),
).unpivot(
on=["Vol (USD)", "Vol (RAI)", "Vol (ETH)"],
index="datetime",
value_name="Volume",
variable_name="Token",
).sort("datetime", descending=True)
volume_df.head(10)
fig1 = px.bar(volume_df, x="datetime", y="Volume", facet_row="Token", title="Volume", barmode="group", labels={"datetime":"Time", "Volume":""})
fig1.update_yaxes(matches=None)
fig1.for_each_annotation(lambda a: a.update(text=a.text.split("=")[-1]))
fig1.show()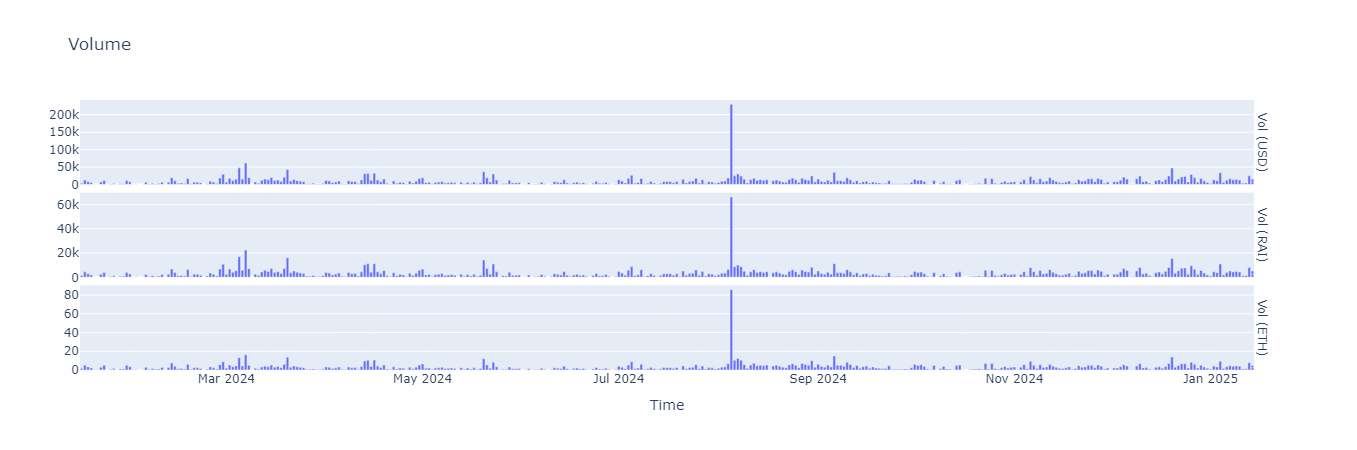
2. Liquidity: The sync event shows us the reserves on each side of the pool. Convert reserves in ETH terms to USD. Since UniswapV2 ensures that both sides of the pool have equal value, double the USD value of the reserve is the total liquidity.
liquidity_df = sync_df.select(
pl.col("block_timestamp").dt.date().alias("datetime"),
(pl.col("reserve0")/1e18).alias("Reserve (RAI tokens)"),
(pl.col("reserve1")/1e18).alias("Reserve (ETH tokens)"),
).group_by(["datetime"]).agg(
pl.col("Reserve (RAI tokens)").last().alias("Reserve (RAI tokens)"),
pl.col("Reserve (ETH tokens)").last().alias("Reserve (ETH tokens)"),
).join(
eth_price_df, on="datetime", how="inner"
).with_columns(
(pl.col("Reserve (ETH tokens)")*pl.col("eth_price_usd")).alias("Liquidity (USD)"),
(2*pl.col("Reserve (ETH tokens)")*pl.col("eth_price_usd")).alias("Total Liquidity (USD)"),
).sort("datetime", descending=True)
fig2 = px.line(liquidity_df, x="datetime", y=["Total Liquidity (USD)", "Reserve (RAI tokens)", "Reserve (ETH tokens)"], title="Liquidity", labels={"datetime":"Time", "value":"Liquidity"})
fig2.show()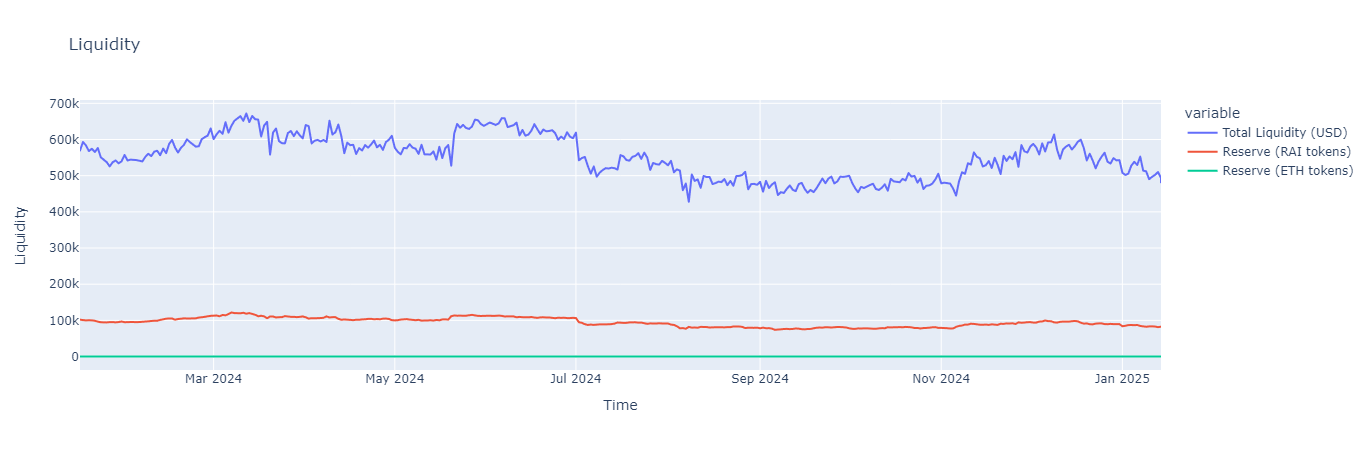
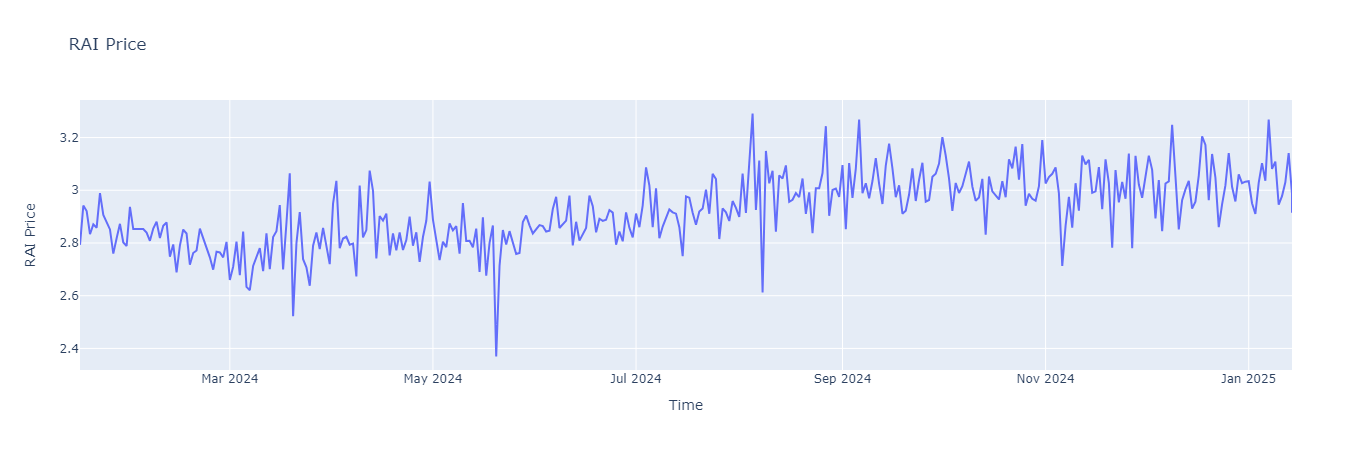
3. Price: Calculate the price of RAI by dividing the USD value of the ETH side by the total tokens on the RAI side.
RAI_price_df = liquidity_df.with_columns(
(pl.col("Liquidity (USD)")/pl.col("Reserve (RAI tokens)")).alias("RAI Price"),
)
fig3 = px.line(RAI_price_df, x="datetime", y="RAI Price", title="RAI Price", labels={"datetime":"Time"})
fig3.show()